

Picture this: It’s 2AM, you’re awake (again), and the internet is being reconfigured by swarms of tireless AIs reconstructing reality while you microwave leftover pizza. Welcome to a world where open-source tools like Tencent’s HunyuanWorld-Mirror and its digital cousins stretch the limits of creativity—and, honestly, make you wonder who (or what) is really dreaming up our future worlds. Let’s stumble down this AI rabbit hole together, fueled by insomnia, curiosity, and maybe just a hint of cosmic dread.
1. AI’s Never-Ending Energy: How Open-Source 3D Generation Upended My Sleep Schedule
If you’ve ever tried to keep pace with the world of AI Vision and 3D Generation, you know the feeling: AI never sleeps and this week has been absolutely insane. That quote sums up my life lately. Every time I think I’ve caught up, another open-source breakthrough drops—usually just as I’m about to log off for the night. The result? More than a few 3AM “eureka!” moments, fueled by the relentless energy of open-source AI.
Relentless Innovation: The Open-Source AI Tsunami
This isn’t just hype. In the past few weeks alone, we’ve seen a tidal wave of new tools for 3D Generation and high-resolution video creation. Models like HunyuanWorld-Mirror (from Tencent), Dype, and Ultra Gen are all open-source and free—no paywalls, no exclusive hardware, just download and go. If you have a CUDA-enabled GPU, you’re in the game.
The pace is dizzying. One day, you’re marveling at AI that natively generates ultra-high-res images. The next, you’re testing a model that spits out 4K videos—no upscaling tricks, just pure, native detail. And it’s not just images and videos: Google’s new quantum computing leap, OpenAI’s ChatGPT Atlas browser, and semantic 3D model editors are all raising the bar for what’s possible.
Why the Late-Night Code Sprints?
Let’s be honest: part of the reason my sleep schedule is a mess is pure excitement. When HunyuanWorld-Mirror landed on Hugging Face, complete with examples, documentation, and a buzzing community, I couldn’t resist. Suddenly, I was generating 3D worlds and tweaking prompts at hours when I should have been asleep. The open-source spirit means you’re not just a user—you’re a tester, a breaker, a remixer. Every new release is a playground, and the only limit is how late you’re willing to stay up.
Native 4K Generation: No More Upscaling Tricks
The leap to native 4K video and image generation is a game-changer. Previously, getting crisp, detailed visuals meant generating at lower resolutions and then upscaling—often with mixed results. Now, models like Dype and Ultra Gen can create native 4K output, with Ultra Gen standing out for both speed and quality.
For example, Ultra Gen can generate a 4K video in under 2 hours, compared to about 9 hours for leading competitors like One. That’s not just a technical win—it’s a creative one. You can iterate faster, experiment more, and push the boundaries of what AI Vision can do.
Open-Source AI: Playful Competition and Community Power
There’s a real sense of playful competition in this space. Each new release—whether it’s HunyuanWorld-Mirror, Dype, or Ultra Gen—ups the ante for image quality, speed, and accessibility. The open-source nature means anyone can jump in, test, break, and remix these breakthroughs. That collective energy accelerates innovation in ways closed systems simply can’t match.
- HunyuanWorld-Mirror: Freely available on Hugging Face, with robust documentation and community support.
- Dype: Model size is just ~5GB, making it accessible for consumer GPUs.
- Ultra Gen: Sets a new standard for 4K video generation speed and detail.
With this open access, you don’t need a big-budget lab or exclusive hardware. Anyone with curiosity and a GPU can join the AI Vision revolution.
Ultra Gen vs. Leading Model: 4K Video Generation Time
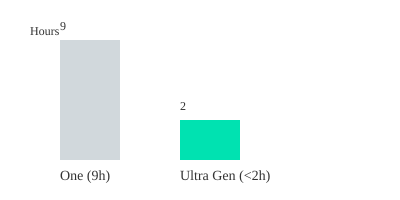
Bar chart: Ultra Gen generates 4K video in under 2 hours; leading model (One) takes ~9 hours.
The boundaries of AI Vision and 3D Generation keep shifting—mostly at 3AM. But with open-source tools like HunyuanWorld-Mirror, Dype, and Ultra Gen, you can be part of the action, no matter when inspiration (or insomnia) strikes.
2. Hunyuan World Mirror: Why This 3D Foundation Model Is Actually a Big Deal
If you’ve ever tried to build a 3D model from a handful of photos, you know how slow and frustrating traditional 3D reconstruction can be. Most tools require lots of manual tweaking, and even then, the results often look patchy or inconsistent. That’s why HunyuanWorld-Mirror, Tencent’s new open-source 3D foundation model, is such a breakthrough for AI-powered 3D generation. It’s not just another photogrammetry tool—it’s a universal, flexible, and surprisingly easy way to turn your images into rich, navigable 3D worlds.
From Your Photos to a Complete 3D World
With HunyuanWorld-Mirror, you can take as few as two photos—or even a short video—and generate a consistent 3D scene. The system doesn’t just guess at the geometry; it actually integrates multiple geometric priors, including depth, surface normals, point clouds, and camera intrinsics. This means you get detailed, accurate reconstructions, whether you’re working with a tunnel, a lighthouse, or a cluttered living room.
What’s truly impressive is how the model handles all the tricky stuff for you. You can feed it images, camera parameters, depth maps, and pose data. In a single forward pass, HunyuanWorld-Mirror outputs not only the 3D world, but also camera positions, depth maps, and normal estimations—all at once. This is a huge leap from the slow, brittle pipelines of the past.
This has got to be the most flexible open source 3D world generator you can use right now.
Universal Geometric Prediction: The Secret Sauce
The real magic behind HunyuanWorld-Mirror is its approach to Universal Geometric Prediction. Instead of building separate models for each 3D task, Tencent’s team created a single model that can handle everything—from reconstructing full 3D scenes to generating point clouds or even producing Gaussian representations. This means you can experiment with different types of outputs, all from the same set of inputs.
- Scene-scale 3D Reconstruction: Build entire rooms or outdoor spaces from just a few images.
- Point Clouds & Surface Normals: Get detailed geometric data for further editing or analysis.
- 360° World Generation: Create immersive, navigable environments for VR, gaming, or simulation.
Personally, watching HunyuanWorld-Mirror recreate a room from my awkward phone photos gave me chills. The model not only recognized the positions from which I took the pictures, but also filled in fine details—windows, flags, even subtle lighting differences. It’s a level of fidelity that used to require expensive, specialized equipment and hours of manual work.
Open Source and Ready for Experimentation
One of the best things about HunyuanWorld-Mirror is its accessibility. The full model and code are available on Hugging Face and GitHub, complete with instructions for running everything locally. The model files are about 5GB in total—manageable for most modern systems with a CUDA GPU. If you’re curious about 3D reconstruction or want to experiment with AI-powered 3D generation, you can get started right away.
| Feature | Details |
|---|---|
| Model Size | ~5GB |
| Input Types | Images, camera parameters, depth maps, pose data |
| Output Types | 3D scenes, point clouds, surface normals, depth maps |
| Availability | Open source (Hugging Face, GitHub) |
| Release Year | 2024 |
HunyuanWorld-Mirror is more than just a technical achievement—it’s a sign of how quickly universal geometric prediction and AI-powered 3D generation are moving from research labs to your desktop. Whether you’re a developer, artist, or just a curious tinkerer, this is a tool that invites you to dream—and build—in 3D.
3. Pictures into Places: The Magic (and Messiness) of 3D Reconstruction
If you’ve ever wished your photos could become walkable worlds, 3D reconstruction is the bridge between pixels and places. Most 3D models you see online are patchwork creations—stitched together from countless images, each one capturing a different angle or detail. Now, with tools like Tencent’s Hunyuan World Mirror, you can turn a handful of snapshots into a detailed, explorable 3D world. The process isn’t perfect, but it’s surprisingly close to magic.
From Snapshots to Spatial Scenes
Imagine you just came back from a vacation. Instead of scrolling through flat selfies and landscapes, you upload your favorite shots into World Mirror. Suddenly, you’re not just looking at your trip—you’re inside it, virtually walking through the rooms, tunnels, or gardens you visited. This is the promise of modern 3D World Generation: transforming fragmented photos into immersive environments.
“You can upload four photos of this imaginary room like this, and it can stitch them together.”
World Mirror stands out because it doesn’t just guess what’s between your photos. It uses advanced AI to estimate camera parameters—figuring out exactly where each photo was taken from, and at what angle. This means you can actually see the virtual camera positions mapped onto your reconstructed scene, helping you understand coverage and spot missing areas.
The Art (and Science) of Stitching Scenes
Effective 3D reconstruction depends on the quality and variety of your input images. Think of your photos as puzzle pieces: the more angles, overlaps, and details you provide, the more complete and accurate your virtual world becomes. World Mirror lets you use as few as two images, but the results improve dramatically with four, eight, or even more. Multiple zoom levels and perspectives help fill in gaps, reducing errors like missing walls or blurry corners.
But it’s not always perfect. Incomplete data can lead to funny artifacts—floating objects, warped geometry, or strange shadows. Sometimes, you’ll see “holes” where the AI couldn’t guess what should be there. It’s a reminder that while AI is powerful, it still benefits from good camera angles and thoughtful composition.
Point Clouds, Depth Maps, and More
World Mirror doesn’t just give you a pretty 3D model. You can choose from several output types:
- 3D Point Map: A cloud of colored dots showing the structure of your scene.
- Complete Scene: Full geometry for a walkable world.
- Gaussian Scene: A smooth, probabilistic rendering of the space.
- Normals & Depth Maps: Technical layers that help with lighting and realism.
- Camera Positions: Visual markers showing where each photo was taken.
| Input Photos | Camera Parameters Estimated | Output Types | Special Features |
|---|---|---|---|
| 2, 4, or more | Yes (visualized in scene) | Point Map, Complete Scene, Gaussian Scene, Normals, Depth Maps | Supports depth/normal estimation, camera pose mapping |
Open-Source Freedom and Tinkering
One of the best parts? World Mirror is fully open-source. You can download the models (just 5GB) from Hugging Face and follow step-by-step guides on GitHub. If you have a consumer GPU with at least 5GB of VRAM, you’re ready to experiment. This openness means you’re free to tinker, break, or perfect the reconstruction process—whether you’re a hobbyist, a researcher, or just curious.
Scene quality ultimately depends on your input: image variety, composition, and overlap are key. Built-in estimation tools help you visualize camera positions and coverage, making it easier to plan your next shoot for even better results. And while occasional gaps or artifacts remind us that AI isn’t magic, the ability to turn scattered photos into explorable worlds is nothing short of remarkable.
4. Multi-Modal Prior Prompting: Mixing Images, Depth, and Data Like a Master Chef
If you’ve ever tried to reconstruct a 3D scene from just a few photos, you know the results can be hit-or-miss. That’s where Multi-Modal Prior Prompting comes in—a game-changing approach at the heart of Tencent’s Hunyuan World Mirror. Think of it like a master chef who doesn’t just use one ingredient, but blends a whole pantry of flavors—images, depth maps, camera intrinsics, and pose data—to cook up a rich, detailed 3D world.
World Mirror’s Secret Sauce: Multi-Modal Data Fusion
The real magic behind World Mirror’s 3D reconstruction is its ability to combine multiple types of input data. You’re not limited to just uploading a single photo. Instead, you can mix and match:
- One or more reference images
- Depth maps (if you have them from a phone or depth camera)
- Camera intrinsics (details about your camera’s lens and sensor)
- Camera pose (where the camera was positioned and pointed)
The more you add, the better the result. This is the essence of multi-modal prior prompting: each “ingredient” you provide gives the AI a richer understanding of the scene’s geometry, lighting, and structure. The result? More robust, realistic, and reliable 3D reconstructions—even when your input data is sparse or comes from wildly different angles.
Testing the Recipe: Real-World Anecdotes
During hands-on tests, feeding World Mirror photos of the same room from very different perspectives produced far richer reconstructions than sticking to similar angles. The system accurately estimated camera positions—“Plus, notice the boxes over here. These are where it estimates the cameras were placed...”—and generated detailed point clouds and surface normals. Even with just two or four photos, it could output a nearly complete 3D scene, capturing fine details like windows, flags, and even subtle room textures.
Robust to Mixed or Missing Data
One of World Mirror’s standout features is its flexibility. If you only have images, it does its best. Add depth maps, and the model gets even better. Missing camera intrinsics? No problem—the system is designed to handle real-world data variance and sparsity. This robustness is crucial for practical 3D reconstruction, where perfect data is rare.
Universal Geometric Prediction: Consistency Across Inputs
World Mirror’s architecture rides on what’s called Universal Geometric Prediction. By fusing all available modalities, it ensures consistent outputs—whether you’re aiming for a simple depth map, a detailed point cloud, or a fully reconstructed 3D scene. The documentation even provides best practices for combining inputs, so you can get the most out of your data.
Primed for the Future: Text-to-3D and Beyond
While World Mirror already excels at multi-modal input, its feed-forward model is built for future expansion. Imagine mixing not just images and depth, but also text prompts, video clips, or hybrid data sources. This flexibility means the platform is ready for the next generation of scene understanding, AR overlays, and novel view synthesis.
The Master Chef Analogy: Each Input Adds Flavor
Think of World Mirror as a chef balancing strange ingredients. Each input—an image, a depth map, a camera pose—adds a unique “flavor” to the final 3D world. The more varied and complete your data, the more nuanced and convincing your reconstruction becomes. As the documentation suggests: The recipe is simple—combine reference photos with as much metadata as possible.
This can also generate basically a complete 3D scene.
With Multi-Modal Prior Prompting, you’re not just reconstructing geometry—you’re giving the AI a full pantry to work with, unlocking new levels of realism and flexibility in 3D generation.
5. Who Wins in the Wonder Olympics? Comparing 3D Generation Models Side-by-Side
When it comes to AI-powered 3D generation, it’s not just about World Mirror anymore. The field is packed with contenders like DyPE (for ultra-detailed images), Ultra Gen (native 4K video generation), Hunyuan, and open-source mainstays like One. Each model brings something unique to the table, but when you put them head-to-head, clear winners emerge—especially if you care about speed, clarity, and next-level detail.
Direct Comparisons: Ultra Gen vs. The Field
Let’s get straight to the numbers. As the creators themselves put it:
Here are some comparisons with the leading open source models out there, including Honey One video and One.
Ultra Gen stands out for its ability to generate true 4K video. While other models like One and Hunyuan can technically output higher resolutions, the results are often blurry, lacking the crispness and fine detail that make 3D scenes truly immersive. For example, when you look at a generated mountain landscape, Ultra Gen’s 4K output lets you see the texture of the rocks and the subtle gradients in the snow—details that simply vanish with the competition.
Speed and Resolution: The Numbers Don’t Lie
Generation time is a huge factor, especially if you’re working on tight deadlines or want to iterate quickly. Here’s a side-by-side look at how the leading models stack up for 1080p and 4K video generation:
| Model | 1080p Video Time | 4K Video Time | Model Size |
|---|---|---|---|
| One | ~35 min | ~9 hours (blurry) | ~7GB |
| Hunyuan | ~30 min | Not natively supported | ~6GB |
| Ultra Gen | <17 min | <2 hours (crisp 4K) | ~8GB |
| DyPE (images) | N/A | N/A | ~5GB |
Ultra Gen: 4K Video Generation at Sci-Fi Speeds
For both 1080p and 4K videos, Ultra Gen just beats the rest of the leading video models for most of these benchmarks. If you ask One to generate a 1080p video, you’ll wait about 35 minutes. Ultra Gen does it in less than half that time. But the real jaw-dropper is 4K: One takes nearly nine hours and the result is still blurry. Ultra Gen? Under two hours, and the output is stunningly sharp. As the creators highlight:
The resolution is just a lot clearer and better. Everything is just a lot more detailed.
Whether it’s a volcanic eruption, a coral reef, or a tranquil river, Ultra Gen’s results look like something straight out of a high-end CGI studio. Watching it churn out a high-res volcanic eruption in under two hours honestly felt like a scene from sci-fi.
DyPE: Super-Resolution for Still Images
While Ultra Gen takes the crown for video, DyPE is pushing the limits for still images. DyPE can take older open-source models and enhance them, packing much sharper details into every pixel. In direct comparisons—like Flux vs. DyPE at 4K—the difference is striking. You can zoom into a snowy village at dusk and actually make out the window frames and rooftops, something other models simply can’t deliver.
Community Competition: The AI Arms Race
All this rapid progress is fueled by fierce community competition. New features and improvements drop fast because nobody wants to get left behind in the AI-powered 3D generation race. The result? Quality is skyrocketing, and the whole scene feels like the video game ‘Olympics’ for AIs.
4K Video Generation Time by Model
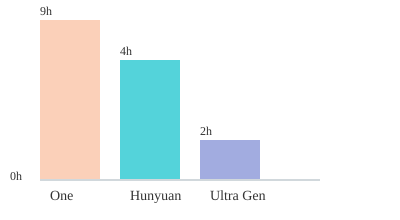
Chart: 4K video generation times (hours) by model. Lower is better.
6. From Code to Creativity: Imagining the Wild Uses (and Oddities) of AI-Powered 3D Worlds
When you think of AI-Powered 3D Generation, it’s easy to imagine blockbuster movies or next-gen video games. But with open source AI like Tencent’s Hunyuan World Mirror now available for anyone with a CUDA GPU and a 5GB download, the possibilities for virtual world use cases have exploded far beyond entertainment. Everyday users and tinkerers can now access tools once reserved for professional studios—ushering in a new era where digital reality is both weird and wonderful.
Beyond Gaming: Practical and Playful Uses for Open Source AI
Let’s start with the practical. With Hunyuan World Mirror, you can photoscan your entire apartment using just a few images, then generate a detailed 3D model of your living space. Imagine digitally rearranging your furniture, testing new paint colors, or even visualizing a full remodel—before you ever hire movers or lift a brush. This isn’t science fiction; it’s a real workflow you can try at home, thanks to open source AI.
- Interior Design & Real Estate: Create virtual tours for buyers, or collaborate on layouts with your family in real time.
- Architecture & Digital Twins: Build accurate 3D models of buildings for planning, safety, or historical preservation.
- Virtual Tourism: Walk through a lighthouse, tunnel, or ancient city reconstructed from photos, all without leaving your chair.
- Education & VR Memories: Capture classrooms, museums, or even your childhood home for immersive learning or nostalgia trips.
- Art & Film Pre-Visualization: Experiment with surreal installations or storyboard entire scenes with photorealistic detail.
When AI Gets Creative (or Just Plain Weird)
Of course, not every AI-generated 3D world is perfect. Sometimes, the oddities are half the fun. Glitches—like floating windows, warped flags, or impossible shadows—can turn a virtual tour into a surreal art experience. These quirks are both a source of unintended comedy and a reminder of the technology’s current limits. It’s not hard to imagine a future where you could “deepfake” your own reality by swapping out your furniture or even your walls in a virtual walkthrough. Will your friends ever know what your real living room looks like?
And then there’s the wild card: What happens when you integrate humanoid robot integration into these AI-powered 3D worlds? With this week’s “moderately creepy” robot demos, it’s not far-fetched to picture a pie-eating robot curating your next virtual museum tour. Will robots become our digital docents, guiding us through AI-generated galleries filled with both masterpieces and delightful glitches?
We have some new and moderately creepy humanoid robot demos and a lot more, so let's jump right in.
Personal Aside: The Joy of Unexpected Guests
On a lighter note, I can’t help but imagine my dog photobombing every AI-generated scene—tail wagging, tongue out, popping up in the middle of a reconstructed tunnel or lounging in a virtual garden. She’d love it, and honestly, so would I. It’s these playful, unexpected moments that remind us: digital worlds are only as serious (or silly) as we make them.
Ethics, Accuracy, and the Blurring Line of Reality
With Open Source AI lowering the cost of experimentation, anyone can build, remix, or share 3D worlds. But as barriers disappear, new questions arise. How accurate are these reconstructions? Could someone “deepfake” your home or office for malicious purposes? Where do we draw the line between simulation and reality? As you explore these tools, it’s important to consider privacy, realism, and the ethics of digital replication.
Still, the benefits are hard to ignore. Whether you’re a designer, educator, artist, or just a curious explorer, the new wave of AI-powered 3D generation tools lets you reimagine the world—one pixel (and maybe one pie-eating robot) at a time.
7. FAQs on HunyuanWorld-Mirror and the Open-Source 3D Revolution
What are the hardware requirements for running HunyuanWorld-Mirror?
If you’re eager to experiment with HunyuanWorld-Mirror, you’ll be happy to know that the hardware barrier is lower than you might expect for such a powerful 3D generation tool. The main requirement is a CUDA-enabled GPU with at least 5GB of VRAM, which covers most modern consumer graphics cards released in the past few years. The model itself is about 5GB in size, so you’ll want enough storage space as well. With these specs, you can run HunyuanWorld-Mirror locally and enjoy fast, interactive 3D reconstructions. This accessibility is a big part of why open source AI is making such rapid progress in 2024.
Is it truly open-source, and where can I get it?
Yes, HunyuanWorld-Mirror is fully open-source, reflecting Tencent’s commitment to community-driven AI innovation. You can find the official models on Hugging Face and the complete codebase, along with detailed instructions, on GitHub. This means you’re free to download, modify, and even contribute to the project. The documentation is robust, and the community is active—so if you get stuck, help is just a forum post or GitHub issue away. If you're interested in reading further, I'll link to this main page in the description below.
How accurate are the 3D reconstructions, really?
The accuracy of HunyuanWorld-Mirror’s 3D reconstructions is genuinely impressive, especially considering its open-source status. The tool can stitch together multiple photos, estimate camera positions, and generate detailed 3D point clouds and full scenes. However, the quality of your results depends on the quality and diversity of your input data. Simple, well-lit scenes with clear reference images yield the best results. Complex environments or poor-quality images may introduce artifacts or less precise geometry. Still, for most users, the level of detail—such as windows, flags, and even subtle textures—will be more than enough for both creative and technical projects.
Can I use these tools for commercial projects?
Most of the open-source 3D generation tools discussed here, including HunyuanWorld-Mirror, are released under permissive licenses that allow for commercial use. However, you should always check the specific license in the GitHub repository before deploying in a business or product context. The open-source AI movement is designed to empower both hobbyists and professionals, but respecting individual project licenses ensures the ecosystem remains healthy and sustainable.
What are ‘point clouds’ and ‘Gaussian scenes’ in plain English?
If you’re new to 3D generation, terms like “point clouds” and “Gaussian scenes” can sound intimidating. In simple terms, a point cloud is a set of data points in space—think of it as a digital scatter plot that maps the shape of an object or scene. Each point represents a spot on the surface of whatever you’re modeling. Gaussian scenes refer to a method of representing 3D objects using mathematical “blobs” (Gaussians) that smoothly blend together. This approach helps create more realistic, continuous surfaces and textures, making your 3D worlds look less blocky and more lifelike.
Are there risks (privacy, copyright, ethical) to be aware of?
As with any advanced AI tool, there are important ethical and legal considerations. If you use copyrighted images or data as input, you could run into intellectual property issues—always use materials you have rights to. Privacy is another concern: avoid uploading personal or sensitive images, especially if you’re sharing results online. Ethically, these tools can be used for both creative and questionable purposes, so it’s up to you to act responsibly. The open-source community is proactive about these topics, and you’ll find ongoing discussions and guidance in project forums and documentation.
In summary, the open-source 3D revolution, led by tools like HunyuanWorld-Mirror, is more accessible than ever. With modest hardware, strong community support, and clear documentation, you can dive into the world of AI-powered 3D generation—whether you’re a curious beginner or a seasoned creator. The future is open, and the possibilities are as limitless as your imagination.
TL;DR: Open-source AIs like Tencent's HunyuanWorld-Mirror are revolutionizing 3D world generation—offering flexible, detailed, and accessible tools for techies, artists, and the merely curious. With breakthroughs in video, image, and even humanoid robotics, it's clear: Some of the most exciting (and surreal) ideas spring from digital minds that never sleep.
Post a Comment